iOS10:用 Speech 框架創建語音輸入App
在 2016 WWDC 大會上,蘋果推出了可以用於語音識別的 Speech Kit 框架。實際上,Siri 就是用 Speech Kit 框架來進行語音識別的。其實現在已經有一些語音識別框架了,但它們要麼太貴,要麼用法復雜。在本教程中,我將使用 Speech Kit 創建一個類似 Siri 的 app 用於將語音轉換成文本。
創建 UI
[ecko_alert color=”green”]前提: 你需要擁有 Xcode 8 beta 以及一台搭載 iOS 10 的設備。[/ecko_alert]
新建一個名為 SpeechToTextDemo 的專案。打開 Main.storyboard ,拖入一個 UILabel、一個 UITextView 以及一個 UIButton。
最終效果如下:
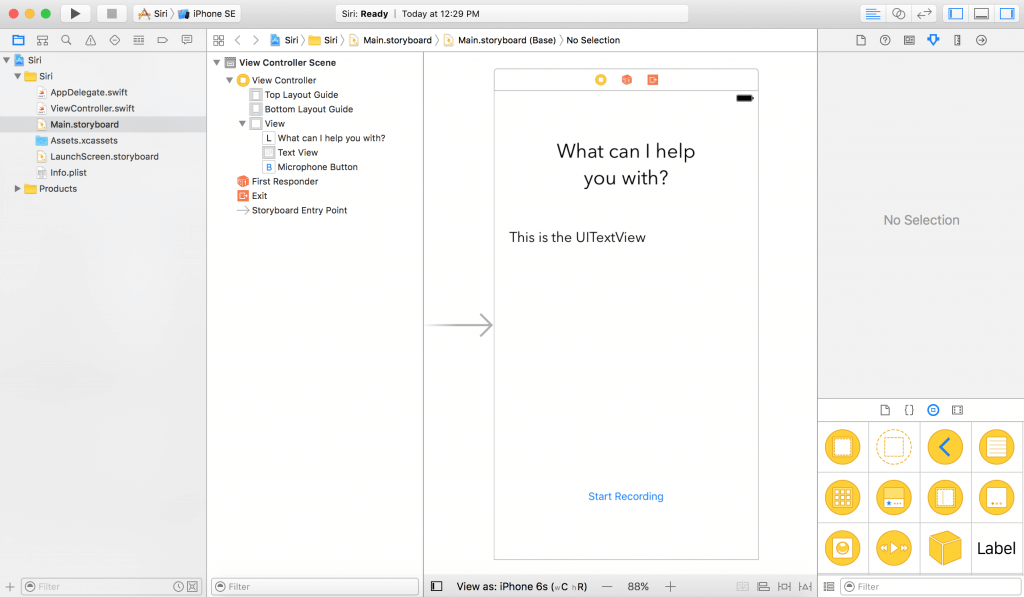
然後在 ViewController.swift 中,分別為 UITextView 和 UIButton 創建相應的 IBOutlet 變量。在這個 demo 中,我用 “textView” 變量引用 UITextView,用 “microphoneButton” 變量來引用 UIButton 。然後創建一個空的 IBAction 方法,用於處理麥克風按鈕被點擊的事件:
@IBAction func microphoneTapped(_ sender: AnyObject) {
}
如果你不想從頭開始,你可以從 這裡下載初始項目 並繼續後面的內容。
使用 Speech Framework
要使用 Speech framework,你首先要 import 這個框架並實現 SFSpeechRecognizerDelegate 協議。先 import 這個框架,然後將這個協議添加到類 ViewController 的聲明中。現在的 ViewController.swift 應該是這個樣子:
import UIKit
import Speech
class ViewController: UIViewController, SFSpeechRecognizerDelegate {
@IBOutlet weak var textView: UITextView!
@IBOutlet weak var microphoneButton: UIButton!
override func viewDidLoad() {
super.viewDidLoad()
}
@IBAction func microphoneTapped(_ sender: AnyObject) {
}
}
用戶授權
在進行語音識別之前,你必須獲得用戶的相應授權,因為語音識別並不是在 iOS 設備本地進行識別,而是在蘋果的服務器上進行識別的。所有的語音數據都需要傳給蘋果的後台服務器進行處理。因此必須得到用戶的授權。
我們先在 viewDidLoad 方法中獲取用戶授權。用戶應當允許我們的 app 使用聲頻輸入和語音識別。首先聲明一個 speechRecognizer 變量:
private let speechRecognizer = SFSpeechRecognizer(locale: Locale.init(identifier: "en-US")) //1
然後修改 viewDidLoad 方法為:
override func viewDidLoad() {
super.viewDidLoad()
microphoneButton.isEnabled = false //2
speechRecognizer.delegate = self //3
SFSpeechRecognizer.requestAuthorization { (authStatus) in //4
var isButtonEnabled = false
switch authStatus { //5
case .authorized:
isButtonEnabled = true
case .denied:
isButtonEnabled = false
print("User denied access to speech recognition")
case .restricted:
isButtonEnabled = false
print("Speech recognition restricted on this device")
case .notDetermined:
isButtonEnabled = false
print("Speech recognition not yet authorized")
}
OperationQueue.main.addOperation() {
self.microphoneButton.isEnabled = isButtonEnabled
}
}
}
首先,我們創建了一個 SFSpeechRecognizer 對象,並指定其 locale identifier 為 en-US,也就是通知語音識別器用戶所使用的語言。這個對象將用於語音識別。
默認,我們將禁用 microphone 按鈕,一直到語音識別器被激活。
將語音識別器的 delgate 設為 self,也就是我們的 ViewController。
然後,調用 SFSpeechRecognizer.requestAuthorization 獲得語音識別的授權。
最後,判斷授權狀態,如果用戶已授權,enable 麥克風按鈕。否則打印錯誤信息並禁用麥克風按鈕。
你可能以為現在運行 app 就能看到用戶授權提示了,其實不然。當你運行 app,app 會崩潰。這是什麼鬼?
提供授權信息
蘋果需要你為每個授權指定一個定制的消息文本。就 Speech framework 而言,我們必須獲得兩個授權:
使用麥克風語音識別
要定制這些授權消息,你必須在 info.plist 文件中設置一些值。
以 Source Code 方式打開 info.plist 文件。首先,在 info.plist 文件上點擊右鍵,然後依次選擇 Open As > Source Code 菜單。然後,拷貝下面的 XML 並將之插入到 標簽之前.
NSMicrophoneUsageDescription 當你按下“開始識別”並開始講話時,將使用麥克風進行錄音。 NSSpeechRecognitionUsageDescription 當你對著麥克風說話時,將進行語音識別。
這會在 info.plist 文件中增加兩個 key:
NSMicrophoneUsageDescription - 這個 key 用於指定錄音設備授權信息。注意,只有在用戶點擊麥克風按鈕時,這條信息才會顯示。 NSSpeechRecognitionUsageDescription -這個 key 用於指定語音識別授權信息。你可以隨意指定這些字符串的值。現在,請點擊 Run 編譯和運行 app,錯誤不再出現。
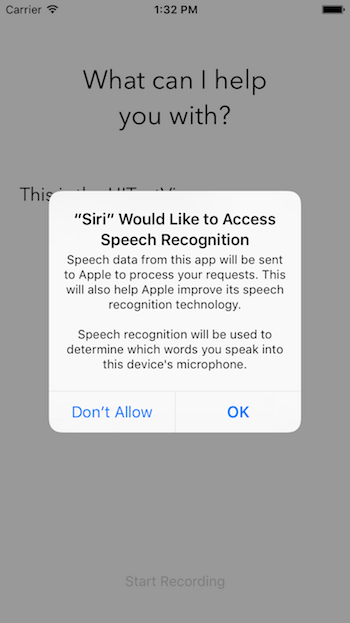
[ecko_alert color=”gray”]備注: 當項目完成後,你不會看到錄音設備授權信息,那麼你可能是正在仿真器上運行 app。仿真器無法訪問 Mac 上的麥克風。[/ecko_alert]
語音識別處理
搞定用戶授權之後,我們來實現語音識別。在 ViewController 中添加如下變量:
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest? private var recognitionTask: SFSpeechRecognitionTask? private let audioEngine = AVAudioEngine()這個對象負責發起語音識別請求。它為語音識別器指定一個音頻輸入源。
這個對象用於保存發起語音識別請求後的返回值。通過這個對象,你可以取消或中止當前的語音識別任務。
這個對象引用了語音引擎。它負責提供錄音輸入。
然後新增一個方法,方法名叫做 startRecording()。
func startRecording() {
if recognitionTask != nil {
recognitionTask?.cancel()
recognitionTask = nil
}
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(AVAudioSessionCategoryRecord)
try audioSession.setMode(AVAudioSessionModeMeasurement)
try audioSession.setActive(true, with: .notifyOthersOnDeactivation)
} catch {
print("audioSession properties weren't set because of an error.")
}
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let inputNode = audioEngine.inputNode else {
fatalError("Audio engine has no input node")
}
guard let recognitionRequest = recognitionRequest else {
fatalError("Unable to create an SFSpeechAudioBufferRecognitionRequest object")
}
recognitionRequest.shouldReportPartialResults = true
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest, resultHandler: { (result, error) in
var isFinal = false
if result != nil {
self.textView.text = result?.bestTranscription.formattedString
isFinal = (result?.isFinal)!
}
if error != nil || isFinal {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
self.microphoneButton.isEnabled = true
}
})
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer, when) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
do {
try audioEngine.start()
} catch {
print("audioEngine couldn't start because of an error.")
}
textView.text = "Say something, I'm listening!"
}
這個方法會在“開始錄音”按鈕被點擊後調用。它的主要功能是開始語音識別和監聽麥克風。讓我們逐行解釋一下這些程序代碼:
行 3-6 - 檢查 recognitionTask 任務是否處於運行狀態。如果是,取消任務,開始新的語音識別任務。行 8-15 - 創建一個 AVAudioSession 用於錄音。將它的 category 設置為 record,mode 設置為 measurement,然後開啟 audio session。因為對這些屬性進行設置有可能導致異常,因此你必須將它們放到 try catch 語句中。
行 17 - 初始化 recognitionRequest 對象。這裡我們創建了一個 SFSpeechAudioBufferRecognitionRequest 對象。在後面,我們會用它將錄音數據轉發給蘋果服務器。
行 19-21 - 檢查 audioEngine (物理設備) 是否擁有有效的錄音設備。如果沒有,我們產生一個致命錯誤。
行 23-25 - 檢查 recognitionRequest 對象是否初始化成功,值不為nil。
行 27 - 告訴 recognitionRequest 在用戶說話的同時,將識別結果分批返回。
Line 29 - 在 speechRecognizer 上調用 recognitionTask 方法開始識別。方法參數中包括一個完成塊。當語音識別引擎每次采集到語音數據、修改當前識別、取消、停止、以及返回最終譯稿時都會調用完成塊。
行 31 - 定義一個 boolean 變量,用於檢查識別是否結束。
行 35 - 如果 result 不為 nil,將 textView.text 設置為 result 的最佳譯稿。如果 result 是最終譯稿,將 isFinal 設置為 true。
行 39-47 - 如果沒有錯誤發生,或者 result 已經結束,停止 audioEngine (錄音) 並終止 recognitionRequest 和 recognitionTask。同時,使 “開始錄音”按鈕可用。
行 50-53 - 向 recognitionRequest 加入一個音頻輸入。注意,可以在啟動 recognitionTask 之後再添加音頻輸入。Speech 框架會在添加完音頻輸入後立即開始識別。
行 55 - 預熱並啟動 audioEngine.
觸發語音識別
當我們新建一個語音識別任務時,我們必須確保語音識別是可用的,因此我們必須在 ViewController 中加入一個委托方法。當語音識別不可用或者狀態發生改變時,應當改變 microphoneButton.enable 屬性。這樣,我們需要實現 SFSpeechRecognizerDelegate 協議的 availabilityDidChange 方法如下所示:
func speechRecognizer(_ speechRecognizer: SFSpeechRecognizer, availabilityDidChange available: Bool) {
if available {
microphoneButton.isEnabled = true
} else {
microphoneButton.isEnabled = false
}
}
當可用狀態發生改變時,該方法被調用。只有在語音識別可用的情況下,錄音按鈕才會啟用。
然後我們需要修改 microphoneTapped(sender:) 方法:
@IBAction func microphoneTapped(_ sender: AnyObject) {
if audioEngine.isRunning {
audioEngine.stop()
recognitionRequest?.endAudio()
microphoneButton.isEnabled = false
microphoneButton.setTitle("Start Recording", for: .normal)
} else {
startRecording()
microphoneButton.setTitle("Stop Recording", for: .normal)
}
}
在這個方法裡,我們必須檢查 audioEngine 是否處於運行狀態。如果是,app 將停止 audioEngine,停止向 recoginitionRequest 輸入音頻數據,禁用 microphoneButton 並將按鈕標題設置為“開始錄音”。
如果 audioEngine 未運行,app 調用 startRecording() 並設置按鈕標題為“停止錄音”。
太好了!你可以測試你的 app 了。將 app 安裝到 iOS 設備,點擊“開始錄音”按鈕。然後開始說話吧!
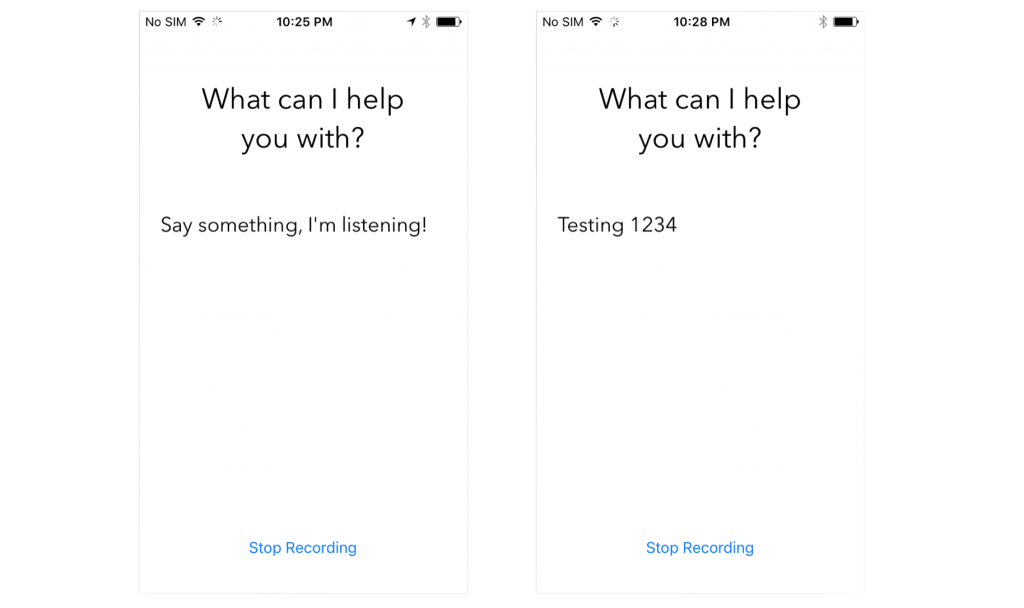
備注:
蘋果公司限制了每台設備的識別次數。限制的次數沒有明確,你可以聯系蘋果公司。蘋果也限制了每個 app 的識別次數。
如果你經常達到這個限制,請和蘋果公司聯系,他們可能會幫你解決這個問題。
語音識別會占用更多的電量和流量。
語音識別的時長一次最多可持續 1 分鐘。
結束
在本文中,你學習了如何使用神奇的新的 Speech 框架,蘋果通過這一神奇的新框架將語音識別和將語音翻譯成文本的能力開放給開發者。在 Siri 中使用了同樣的框架。它是一個相當輕量的 API,但它的功能卻非常強大,允許開發者實現令人贊歎的功能,比如將一個音頻文件轉換成文本。
我建議你看一下 WWDC 2016 session 509。希望你能喜歡這篇文章,並喜歡上這個嶄新的 API 。
另外,你可以從 Github 下載本教程的完整專案.